Analýza URL
Pokud je v SEO něco důležité, technická analýza vašeho webu do toho rozhodně patří. Naše analýza vám dodá přesně to, co k takové analýze je důležité.
Máte v ní možnost si zkontrolovat, jak na tom je váš web v indexaci u vyhledávačů, což se hodí jak pro první úpravy, ale již i kontrolu vašich stránek.
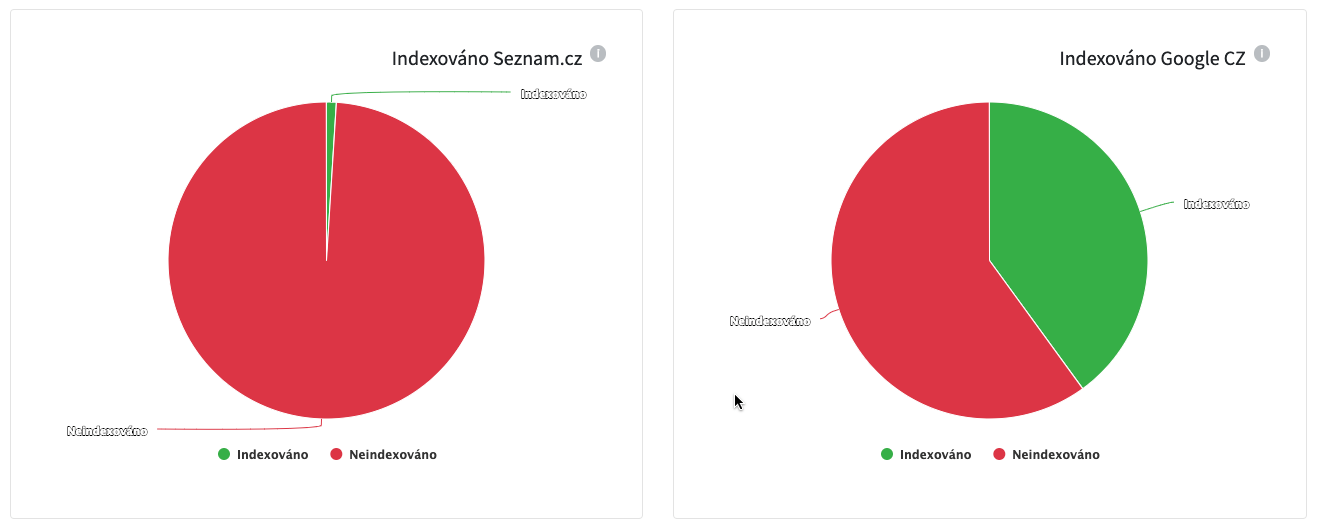
Ukázka webu, co nemá indexaci příliš vyřešenou a Seznam prakticky neví, že web existuje.
Dále je tu možnost také analýzy jednotlivých prvků na vašem webu, jako jsou například titulky, meta descriptiony, nadpisy, atd. Ta je zase důležitá, pokud jste se rozhodli optimalizovat vaše webové stránky pro určitá klíčová slova a chcete zkontrolovat, jak na tom jsou vaše stránky.
A jako další je tu získávač slov z URL, kterým si můžete zjistit, jaká vaše slova se objevují pod vaší webovou stránkou nejčastěji.
Využití v praxi
Možností je několik:
- Pokud začínate se SEO a potřebujete zjistit, jak na tom jste s indexací? Nebo pokud potřebujete pouze zkontrolovat, jak na tom jste s indexací? Jak na kontrolu indexace
- Technická analýza URL, aneb jak posunout váš web na vyšší level s úpravou obsahu na webu
Podívejte se, jak využít analýzu url pro SEO audit
Limit analýzy URL
Analýza URL je limitována určitým počtem URL adres. Tento limit závisí na nastavení analýzy. GSC indexace povolí maximálně 2000 URL pro analýzu, ostatní indexace maximálně 4000 URL. Pokud potřebujete analyzovat větší počet URL adres, je třeba vstupní data pro analýzu eventuálně "rozkouskovat", aby nebyl přesažen limit analýzy.
Možnosti vložení URL:
Jednochuché vložení - prosté vložení URL adres, URL adresy je potřeba oddělovat řádkem
Import z CSV/Excel - zde stačí vložit soubor, URL adresy budou načteny z prvního sloupce importovaného souboru
Sitemap - zadejte URL adresu Vaší adresy a pokud se na ní nachází sitemapa, najdeme si ji a URL adresy vám z ní vytáhneme
GSC - také si můžete nechat vyjet z Google Search Console URL adresy, které byly v posledních dnech zaznamenané
Vysvětlivky sloupců ve výsledcích URL analýzy
První list - Indexation (kontrola stavu indexace webu)
URL - vypsané jednotlivé webové stránky, které byly zadány (po určité filtraci)
Indexed Google - kontrola indexace u vyhledávače Google (TRUE- Stránka je zaindexována | FALSE- Stránka není zaindexována | Co to je indexace?)
Target url Google - cílová zaindexovaná stránka pro Google, která vychází z vepsáné URL adresy při vytváření analýzy
Same as input Google - porovnává sloupec Url a Target url Google, jestli jsou tyto stránky stejné (FALSE - Nejsou stejné / TRUE - Jsou stejné)
Indexed Seznam.cz - kontrola indexace u vyhledávače Seznam (TRUE- Stránka je zaindexována | FALSE- Stránka není zaindexována)
Target url Seznam.cz - cílová zaindexovaná stránka pro Seznam, která vychází z vepsáné URL adresy při vytváření analýzy
Same as input Seznam.cz - porovnává sloupec Url a Target url Seznam.cz, jestli jsou tyto stránky stejné (FALSE - Nejsou stejné / TRUE - Jsou stejné)
Druhý list - Page analyser (technická analýza stránek webu)
URL - vypsané jednotlivé webové stránky, které byly zadány (po určité filtraci)
Page title - titulek dané webové stránky, která byla zadána při vytváření analýzy
Meta description - popisek webové stránky, která byla zadána při vytváření analýzy
H1 Headings - text, který se nachází v nadpisu první úrovně (tagy)
Page size - velikost webové stránky, která byla zadána při vytváření analýzy, v bajtech
Out links count - počet stránek odkazujících ven z dané webové stránky
Load time - čas, za který se načte Vaše webová stránka (v sekundách)
Status code - stavový kód, který značí odpověď Vaší stránky serveru (200 = OK, můžete ale dostat nespočet dalších čísel - stavové kódy)
Created at - datum a čas, v kterém byla provedena kontrola dané webové stránky
Status codes - výpis stavových kódů, přes které se prochází z výchozí (zadané) webové stránky až po koncovou (sloupec Target URL | Jak si pohlídat přesměrování?)
Třetí list - Keyword getter (získávač slov z URL)
URL - vypsané jednotlivé webové stránky, které byly zadány (po určité filtraci)
Keword/Phrase - klíčové slovo / fráze, které byly nalezeny na webové stránce
Is phrase - kontrola, jestli se jedná o frázi, či klíčové slovo *hodí se pro hledání long-tail klíčových slov (TRUE - fráze, FALSE - klíčové slovo)
Points - počet bodů, které určují relevanci daného klíčového slova k webové stránce
H1-H6 - počet výskytů slova v nadpisech první až šesté úrovně
Page title - počet výskytů slova v titulku webové stránky
Strong - výskyt slova v tučném tvaru
Link - jestli dané klíčové slovo je v odkazu na webovou stránku
Link title - počet výskytů klíčového slova v titulcích odkazů
Image title - kolikrát se objevuje dané slovo v titulcích obrázků
Image alt - kolikrát se objevuje dané slovo v alternativním textu obrázku
Meta description - počet výskytů slova v meta description (popisku dané webové stránky)
Meta keywords - počet výskytů slova v meta keywords (klíčová slova, která jsou vepsaná v kódu webové stránky)
Total count in page content - celkový počet výskytů slova na webové stránce
Čtvrtý list - Keyword getter summary (získávač slov z URL - vše najednou)
Všechno zůstává stejné, jen s jednou výjimkou - všechny výpočty se provádí na všech zadaných stránkách.
Příklad..
Máme slovo SEO. Na stránce www.collabim.cz se objevuje třikrát a na stránce www.collabim.cz/akademie se objevuje pouze jednou. Pokud jsme zadali do analýzy obě dvě výše zmiňované stránky, pak v listu Keyword getter summary v sloupci Total count in page content dostaneme číslo čtyři, jelikož výpočet se provádí na všech zadaných webových adresách.
Pátý list - GSC indexation
Url - vypsané jednotlivé webové stránky, které byly zadány (po určité filtraci)
Indexed - kontrola indexace na vyhledávači Google dle Google Search Console (TRUE - Stránka je zaindexována, FALSE - Stránka není zaindexována. Co to je indexace?)
Target URL - cílová zaindexovaná stránka pro Google dle GSC, která vychází z vepsáné URL adresy při vytváření analýzy
Same as input - porovnává sloupec Url a Target URL, jestli jsou tyto stránky stejné (FALSE - Nejsou stejné / TRUE - Jsou stejné)
Verdict - Verdikt pro analýzu dle GSC, může být jedno z:
- VERDICT_
UNSPECIFIED = Neznámý verdikt. - PASS = Platná indexace
- PARTIAL = Platná indexace s upozorněním
- FAIL = Chybná, nebo nevalidní indexace
- NEUTRAL = Vyloučeno z indexace
Coverage state - Informace o indexaci stránky
Indexing state - Podrobnější informace o indexaci stránky, může být jedno z:
- INDEXING_
STATE_ UNSPECIFIED = Neznámý stav indexace - INDEXING_
ALLOWED = Indexace povolena - BLOCKED_
BY_ META_ TAG = Indexace není povolena, v meta tagu "robots" bylo nalezeno "noindex" - BLOCKED_
BY_ HTTP_ HEADER = Indexace není povolena, v hlavičce "X-Robots-Tag" bylo nalezeno "noindex" - BLOCKED_
BY_ ROBOTS_ TXT = Indexace není povolena, v souboru robots.txt bylo nalezeno "noindex"
Robots.txt state - Stav dle souboru robots.txt, může být jedno z:
- ROBOTS_TXT_STATE_UNSPECIFIED = Neznámý stav robots.txt souboru. Toto se obvykle obvykle děje když soubor robots.txt není dostupný
- ALLOWED = Indexace stránky byla povolena pomocí robots.txt
- DISALLOWED = Indexace stránky byla zablokována pomocí robots.txt
Last crawl time - Datum a čas posledního procházení URL pomocí GoogleBota
Page fetch state - Chybový stav stránky při poslední kontrole, možné hodnoty:
- PAGE_FETCH_STATE_UNSPECIFIED = Neznámý stav
- SUCCESSFUL = Úspěšně staženo
- SOFT_404 = Soft 404
- BLOCKED_ROBOTS_TXT = Zablokováno pomocí robots.txt
- NOT_FOUND = Nenalezeno (404)
- ACCESS_DENIED = Neoprávněný požadavek (401)
- SERVER_ERROR = Chyba server (5xx)
- REDIRECT_ERROR = Chyba přesměrování
- ACCESS_FORBIDDEN = Zablokováno z důvodu zakázání přístupu (403)
- BLOCKED_4XX = Zablokováno kvůli jinému problému 4xx (ne 403, 404)
- INTERNAL_CRAWL_ERROR = Interní chyba
- INVALID_URL = Nevalidní URL
Crawled as - Typ robota, který kontrolovat poslední stav indexace, může být jedno z těchto hodnot:
- CRAWLING_
USER_ AGENT_ UNSPECIFIED = Nespecifikováno - DESKTOP = Desktopový User-Agent
- MOBILE = Mobilní User-Agent